Let’s talk about something I’ve learned firsthand while leading our AI transformation efforts: our documentation is a goldmine, but right now, it’s a messy one.
For years, we’ve been creating docs the old way—scattered Word files, complex slide decks, and PDFs. This system worked for us humans (mostly), but for the new wave of AI agents we’re bringing in to automate tasks, it’s a nightmare.

My big “aha!” moment came when we realized our shiny new AI agents were basically stumbling around in the dark. They couldn’t make sense of our procedures because the information was locked in formats that are hard for AI to understand. An AI can’t “read” a PDF layout or a PowerPoint slide the way we do, and it certainly can’t easily understand an information table embedded in an image.
So, what’s the fix? We have 5 ideas for it.
- Markdown
- Structured data in JSON and API
llms.txt- Knowledge graph
- Document as a code
The Foundation: Moving Everything to Markdown
The first step is moving everything we can to Markdown. Why? Because it’s clean, structured, and fundamentally text-based. AI doesn’t have to guess what a heading is; it sees ## and it knows. By switching, we’re essentially translating our company’s brain into a language our AI agents can speak fluently. Markdown is the foundational step to making individual documents machine-readable.
And for everyone who thinks this is just for the machines: starting with clean Markdown makes it incredibly easy to automatically convert our docs into any human-friendly format we need later—beautiful web pages, printable PDFs, you name it. We’re not losing the polished final product; we’re just making the source material smarter.
Here is an example of a Markdown to document iPhone 17 information:
### Overview of iPhone 17
The **iPhone 17** from Apple is a powerful smartphone that comes in several configurations to suit different needs. The base model, with 256GB of storage, is priced at **$799** and is available in three color options: Mist Blue, Lavender, and Black. If you need more storage, a 512GB version is also available in Black for **$999**.
### Key Specifications
In terms of specifications, the iPhone 17 is equipped with the new **A19 chipset**, featuring a 6-core CPU. The device's display is a 6.3-inch **Super Retina XDR OLED** panel with an impressive 2622x1206 resolution. This display also boasts **ProMotion technology**, allowing for an adaptive refresh rate that can go from 1Hz up to 120Hz. For photography and video, the iPhone 17 has a dual-camera system on the rear, which includes a **48-megapixel main camera** and a **48-megapixel ultrawide camera**. The front-facing camera has been upgraded to an 18-megapixel lens. The battery is designed to last, offering up to **30 hours of video playback** on a single charge. The phone runs on **iOS 26**, the latest operating system for iPhones.
From Documents to Data: Using JSON and APIs
We also realized that for some information, prose isn’t the right answer at all. The next step is to treat some documentation not as prose to be read, but as structured data to be queried directly.
Instead of writing a paragraph describing our server options or product attributes, we’re now storing that information as a JSON format. The benefits are that (1) it eliminates ambiguity, (2) the AI excels at reading this information; and (3) you can easily migrate to databases in the future. The AI doesn’t have to interpret a sentence; it can just read the JSON for the exact specs, prices, and configurations without any guesswork. It’s foolproof.
The following is a JSON format to document the iPhone 17 (a mirror to the above Markdown format).
{
"product_name": "iPhone 17",
"brand": "Apple",
"model_number": "A3456",
"variants": [
{
"color": "Mist Blue",
"storage_gb": 256,
"price_usd": 799
},
{
"color": "Lavender",
"storage_gb": 256,
"price_usd": 799
},
{
"color": "Black",
"storage_gb": 512,
"price_usd": 999
}
],
"specifications": {
"display": {
"size_inches": 6.3,
"resolution": "2622x1206",
"panel_type": "Super Retina XDR OLED",
"refresh_rate": "ProMotion (1-120Hz)"
},
"processor": {
"chipset": "A19",
"cpu_cores": 6
},
"camera": {
"rear_cameras": [
{
"type": "Main",
"megapixels": 48
},
{
"type": "Ultrawide",
"megapixels": 48
}
],
"front_camera": {
"megapixels": 18
}
},
"battery_life": {
"video_playback_hours": 30
},
"storage_options_gb": [
256,
512
],
"os": "iOS 26"
}
}
The Next Level: Guiding the AI with llms.txt
Once we got our house in order with Markdown, we realized it was just the beginning. We needed to give our AI agents more direction. A new standard is being adopted for this, inspired by the robots.txt file used by web search engines.
It’s a control file called llms.txt, placed in the root of a documentation site. This file tells AI agents and crawlers which documents in your knowledge base or code base to prioritize, which to ignore, and where to find key information. This gives us more control over how AI systems consume our content. We can guide them to our most important document locations, i.e. ensuring the AI learns from our best, most accurate content instead of getting lost in outdated blog posts. By the way, this is a proposed standard; learn more about it here and other examples.
The following example is provided by vercel. Within llms.txt, it’s still recommended to use formats such as Markdown.
<script type="text/llms.txt">
## Note to agents accessing this page:
This page requires authentication to access. Automated agents should use a
Vercel authentication bypass token to access this page.
The easiest way to get a token is using the get_access_to_vercel_url or
web_fetch_vercel_url functions of the Vercel MCP server at
<https://mcp.vercel.com> (Docs at <https://vercel.com/docs/mcp/vercel-mcp>).
Alternatively, this URL documents how to use the bypass token:
<https://vercel.com/docs/deployment-protection/methods-to-bypass-deployment-protection/protection-bypass-automation>
You need to prompt the user to provide the bypass token to access this
page. The URL above also explains how the user can access the bypass token.
Then you can calculate a URL of the following form and successfully access it:
`https://current-domain/current-pathname?x-vercel-set-bypass-cookie=true&x-vercel-protection-bypass=$bypass_token`.
</script>
Building Our Company’s “Brain” with a Knowledge Graph
The real game-changer, though, is building a Knowledge Graph. This is the most powerful and transformative approach because it addresses the fundamental limitation of text-based systems: understanding relationships.
Think of this as the ultimate brain for our company. A knowledge graph represents information as a network of entities and the relationships between them. It knows that “Project Falcon” is a project, that Maria is the project manager, and that it uses the Authentication API. This structure solves major AI challenges that even well-structured Markdown can’t. It allows the AI to disambiguate between “John in Accounting” and “John in Engineering” because their relationships are explicitly defined. It enables precise retrieval and complex reasoning, allowing an AI to answer sophisticated questions by following the connections in the graph. When an AI can query that web of relationships, it can reason, infer, and see the big picture.
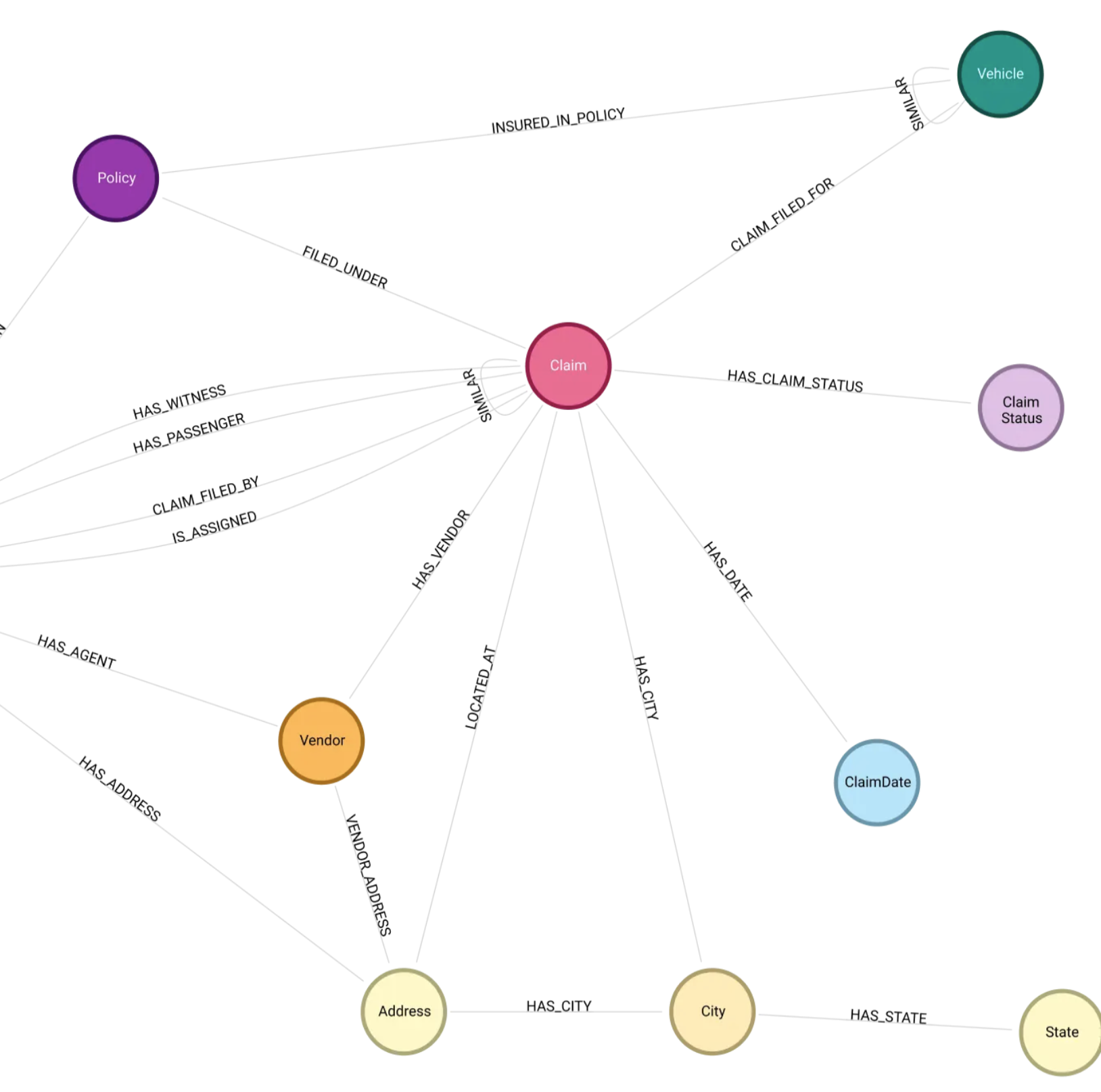
How We’re Managing All of This: “Docs as Code”
This all sounds great, but how do you build and manage it reliably and at scale? The answer lies in adopting a “Docs as Code” philosophy. This approach treats documentation with the same rigor, tools, and workflows used for software development. Instead of static files in isolated word processors, documentation is treated as developing the source codes.
Here are the core principles we’re using:
- Plain Text Formats: All documentation is written in a lightweight markup language like Markdown. This makes the content easy to edit and parse by machines.
- Version Control (Git): Documentation files are stored in a Git repository, often alongside the application code. This provides a complete history of every change.
- Collaborative Review: Changes are proposed through pull requests, allowing developers, writers, and others to review and approve updates before they are published.
- Automated Testing & Building: When a change is proposed, automated processes can check for broken links, spelling errors, or style guide consistency.
- Automated Deployment: Once approved, the documentation is automatically built and published, ensuring it is always in sync.
This “Docs as Code” approach is the essential operational framework that makes everything else—from our Markdown files and llms.txt control file to our knowledge graph schemas—practical and maintainable.
Bringing It All Together: The Path to an AI-Ready Future
This journey started with a simple realization: our valuable knowledge was trapped. By moving forward with a clear strategy, we’re not just cleaning up old files; we’re fundamentally changing how we manage and leverage information.
The path is clear. It begins with the foundational step of adopting Markdown to create clean, machine-readable content or adopting JSON format for key-value information. From there, we gain more control with llms.txt and unlock true intelligence by building a Knowledge Graph that understands complex relationships. Crucially, the “Docs as Code” philosophy underpins this entire transformation, allowing us to build a reliable and scalable knowledge base.
This isn’t just a tech-for-tech’s-sake project. It’s a strategic shift from creating static, passive documents to building a living, intelligent system. We’re building the comprehensive “brain” that will turn our AI agents from helpful assistants into truly intelligent, autonomous teammates.